NSRR staff
Boston, MA
0000-0002-0506-8368
Top Topics
Recent Topics
Adam,
Thanks -- good question. You also asked about versioning in your email to support@sleepdata.org, so I am going to post my reply here about that issue and the race issue you note.
The idea behind our versioning is that the most recent version (0.8.0 for SHHS) would be the “latest and greatest” and would be our suggested starting point for new analyses. From 0.3.0 and onward we broke the dataset into separate CSVs per visit, which would explain why 0.2.0 has more observations in its single file than the files that came later. Also around the switch from 0.2.0 to 0.3.0 we received updated data from the dataset owner (Johns Hopkins in this case) that added more cases to our “CVD Outcomes” dataset. We took down 0.3.0 because it contained records for SHHS subjects that did not consent to share data for future research. Yes, the race data were collapsed into 3 categories by the SHHS dataset owners, which explains the difference between 0.2.0 and 0.4.0+. Our NSRR data mimic what is posted on BioLINCC (https://biolincc.nhlbi.nih.gov/studies/shhs/?q=shhs) – our 0.2.0 version of the data came from a preliminary BioLINCC dataset which did not have the race variable change incorporated yet. Technically one could look back to the older dataset (possibly merging with a newer version) to get the race variable with more fine-grained categories, but we have not carried these data forward into subsequent releases since this is how the dataset owners have immortalized the dataset on BioLINCC. My best guess is that this change was made to more closely match a quasi-standard of how race is presented in BioLINCC datasets. Most datasets that I have seen from BioLINCC have this Black/White/Other breakdown.
The idea behind our versioning is that the most recent version (0.8.0 for SHHS) would be the “latest and greatest” and would be our suggested starting point for new analyses. From 0.3.0 and onward we broke the dataset into separate CSVs per visit, which would explain why 0.2.0 has more observations in its single file than the files that came later. Also around the switch from 0.2.0 to 0.3.0 we received updated data from the dataset owner (Johns Hopkins in this case) that added more cases to our “CVD Outcomes” dataset. We took down 0.3.0 because it contained records for SHHS subjects that did not consent to share data for future research.
Yes, the race data were collapsed into 3 categories by the SHHS dataset owners, which explains the difference between 0.2.0 and 0.4.0+. Our NSRR data mimic what is posted on BioLINCC (https://biolincc.nhlbi.nih.gov/studies/shhs/?q=shhs) – our 0.2.0 version of the data came from a preliminary BioLINCC dataset which did not have the race variable change incorporated yet.
Technically one could look back to the older dataset (possibly merging with a newer version) to get the race variable with more fine-grained categories, but we have not carried these data forward into subsequent releases since this is how the dataset owners have immortalized the dataset on BioLINCC. My best guess is that this change was made to more closely match a quasi-standard of how race is presented in BioLINCC datasets. Most datasets that I have seen from BioLINCC have this Black/White/Other breakdown.
As for your other question about the parent cohorts: There will not be a way to identify the parent cohort of SHHS participants from the NSRR datasets. These links were explicitly removed by the dataset owners as part of the de-identification process when posting on BioLINCC. I believe if you went through BioLINCC to request and obtain access to the parent cohorts (e.g. Framingham, ARIC, etc.) that they may grant access to the linking codes (lookup table with IDs across different data sources).
Hope this helps. Thanks!
Madhvi,
Most of the events in the annotation files were marked by a technician. Each dataset should have an overview of the scoring procedures/rules that should provide the details you mention. For CHAT, that documentation exists here: https://www.sleepdata.org/datasets/chat/pages/manuals/polysomnography-reading-center/6-07-scoring-procedures.md
Let us know if you have further questions. If you want a fuller explanation, I can ask one of our PSG experts to comment. Thanks for using the NSRR!
Matt: Sure, we can plan to do that for consistency's sake in MrOS/SOF in our next releases. Thanks for raising the issue.
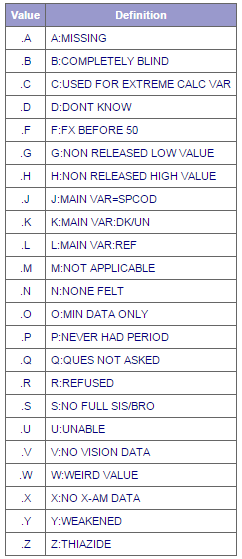
Yep, these are missing codes set by the UCSF group. These were originally SAS missing codes (i.e. .G, .H), which come out as characters in the CSV exports. G and H correspond to values that were scrubbed at the low and high extremes. Unfortunately, we won't be able to get the ages of these subjects.
We will clarify in the next version of the data dictionary. Thanks!
Winda,
There hasn't been any movement on my end toward requesting the SHHS diet/activity data from the individual cohorts.
The topic of soliciting outside data sources for deposition on sleepdata.org was discussed at the user group meeting in October. We agreed to go this route, with our test case coming from Dr. Peppard in Wisconsin. I think 2016 will see us hammering out and refining this process, at which point we will likely reach out to other groups to try and bring them on as collaborators/sharers.
If you wanted to explore obtaining these data on your own, I think BioLINCC would be a good place to start. You can find most of the cohorts that took part in SHHS there, e.g.
https://biolincc.nhlbi.nih.gov/studies/chs/?q=chs https://biolincc.nhlbi.nih.gov/studies/aric/?q=aric https://biolincc.nhlbi.nih.gov/studies/framcohort/?q=framingham
Nice find -- thanks!
Matt,
I am 95% certain the PSG measurements (i.e. EDF/XML and dataset we have on NSRR) correspond with Visit 8.
I took a glance at 'v8sleep.zip' and 'v9sleep.zip' from here: http://sof.ucsf.edu/interface/DataDoc.asp. The "additional sleep measures" in V9 are derived from a night of Masimo Oximeter data, which were also read and scored in our Reading Center. The variables in the V8 sleep dataset align with the variables we generate for our full PSG datasets.
Thanks for checking out the site!
I can confirm that the epochs in the SHHS sleep staging annotations correspond to 30-second windows. This is also correct for other datasets that we currently have EDF and XML annotation files posted for.
For SHHS, I found mention of using the 30-second windows for scoring deep within one of the manuals: https://www.sleepdata.org/datasets/shhs/pages/mop/6-610-mop-overview-of-scoring.md
The 'shhs1' dataset does contain 5,804 records (corresponding to 5,804 overnight sleep studies), but only 5,793 usable EDFs were retrieved from the SHHS archives for posting on sleepdata.org. Unfortunately, those other 11 EDF records were lost over time, most likely due to data corruption at some point long ago.
Nothing comes to mind for me for your request, but I have reached out to some of our signal experts to see if they have any ideas. Thanks for checking out the NSRR!