NSRR staff
Boston, MA
0000-0002-0506-8368
Top Topics
Recent Topics
Thanks for using the site. It sounds like you've encountered artifact. Perhaps you could exclude impossible/implausible values. Certain sensors may not have been worn when the recording started, may have come loose in the middle of the recording, may have been removed before the recording ended, etc.
We (the NSRR) don't have those sort of details. You would probably have to try contacting the equipment manufacturer (Compumedics).
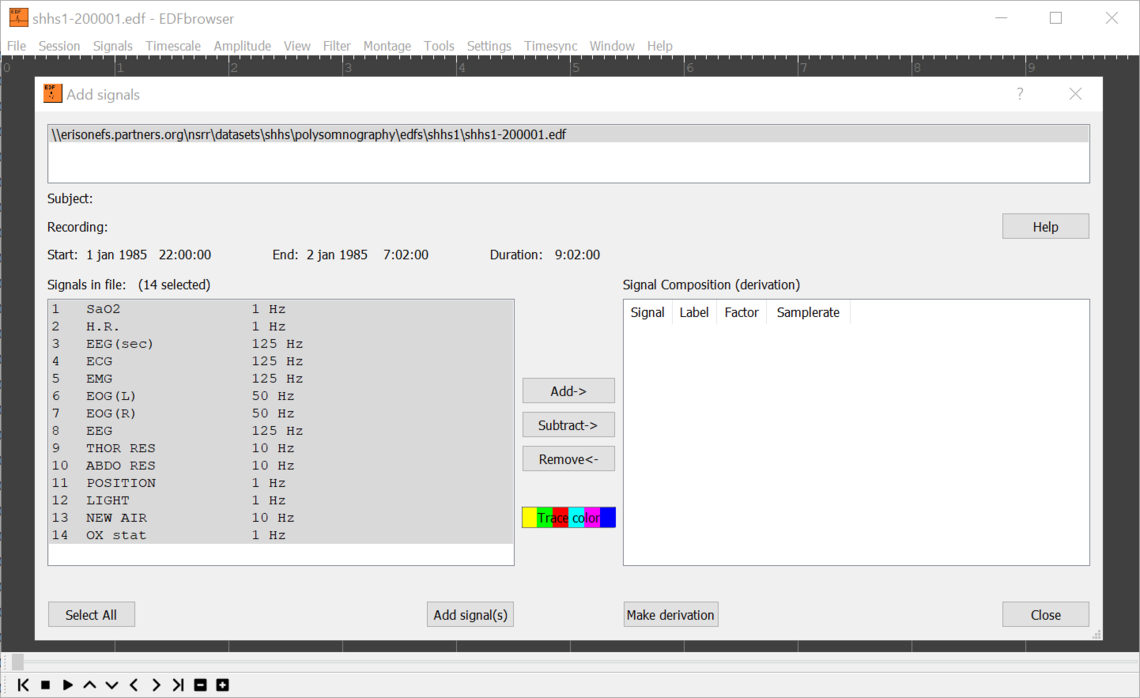
I opened a handful of SHHS EDFs and they all showed a THOR RES channel sampled at 10 Hz. Hence, your calculation of 288,000 data points for an 8 hour recording should be correct.
Did you check how many of the 4 million data points have non-missing data for the THOR RES signal output? If I export an EDF to ASCII from EDFbrowser the output has 1 row per the maximum sampling rate, which is 125 Hz in the example above. However, the THOR RES signal only has values output on the tenths-of-a-second rows.
Thanks for using the site!
To my knowledge, PATS analyses up until this point have often used the maximum tonsil grade (right or left) as a sort of "aggregate" measure.
Thanks for using the site. My best guess is that the NCHSDB data contributors stripped out the "EDF Annotations" channel from the original EDF+ files as part of de-identification, yet left the structure of the signal files indicating they were EDF+. Hence, EDFbrowser sees an invalid EDF+ file and refuses to open it.
I think the Luna tool (https://zzz.bwh.harvard.edu/luna/) would allow you to read in the NCHSDB files and then write them out again as plain EDF files.
Everything we've received from the MNC contributor has been posted. Unfortunately, we (the NSRR) won't be able to provide additional details about such edge cases.
I'm guessing some of the MNC cohorts are fairly old and may have been scored in such a way so as to distinguish N3 from N4 sleep in the staging annotations. Generally, N3 and N4 are now collapsed together to represent "slow wave sleep". E.g., https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2635577/
I suggest treating any uncoded epochs (e.g., 8/9) as unknown/unscored.
Hello - thanks for checking out the site. The MNC data are complete and these gaps/discrepancies have been acknowledged by the contributors. The Excel file and the EDF set were used for varying purposes and are not expected to completely overlap. A little more discussion here: https://sleepdata.org/forum/mignot-dataset-questions/
That is up to you. Many variables have variables that summarize sleep staging and disease status. Otherwise, you may wish to process sleep scoring annotation files to derive new indicators.
Thanks for using the site.
Please reach out to the WSC contact, arasmuson@wisc.edu, to request these additional data.