Data dictionary management with Spout
Spout is an open-source Ruby tool that helps the National Sleep Research Resource team curate, manage, and version-control data dictionaries that describe underlying datasets on the site. These data dictionaries provide metadata about the variables (columns) within a dataset. A well-defined data dictionary is an essential tool for researchers who want to understand and analyze a given dataset.
Background
The NSRR team started development on Spout in 2013. Version 1.0.0 was released on February 1, 2019.
The impetus for Spout was to create a framework in which we could construct data dictionaries and easily deploy them (alongside datasets) to NSRR. Our source datasets contained data dictionaries in varying formats, including Excel, PDF, and Word. We wanted consistently formatted dictionaries across our shared datasets, which is why we created Spout.
From the beginning, we kept three tenets in mind in Spout's development.
- Testing: Ensure that all variables adhere to the JSON format and that basic requirements are met (e.g. units, categorical definitions). Also, provide the user the ability to write additional, custom tests.
- Checking: Provide a simple way to gauge how well the data dictionary overlays the underlying dataset. Flag missing or incomplete metadata to the user to correct and make their data dictionary more complete.
- Versioning: Track every change made to the data dictionary and underlying datasets, such that future users can recreate and see the data dictionary as it was at a specific point in time.
Testing
Spout stores variables and associated metadata as JSON objects. By default, Spout tests whether these files are formatted correctly. When everything looks good, the Spout tests come out looking like this.
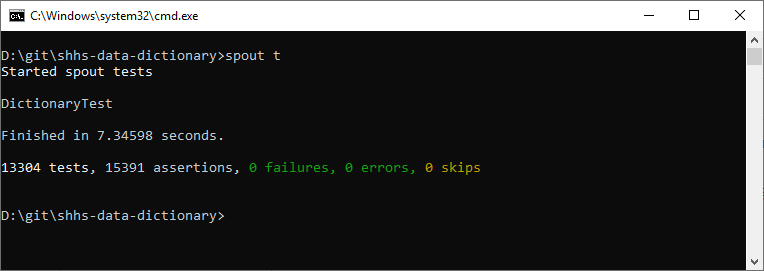
Spout will also test to make sure you don't leave anything out, like the meanings of values for a categorical variable. We call these value meanings "domains". In this case, I forgot to create a domain JSON file that tells Spout (and NSRR users) what 1 and 2 mean for the gender variable.

Users can add their own customized tests that Spout will run alongside its built-in tests with spout test.
Checking
We wanted to ensure that NSRR users would not encounter inconsistencies when working with the data dictionary and dataset. Does every variable in the dataset have a corresponding JSON file in the data dictionary? Are all the values in the dataset described in the data dictionary's domain files? Spout can quickly and easily check these sort of things with the spout coverage command.
In the following example, Spout's checking command brought a missing domain option for the gender variable to the forefront. I was able to revise the domain JSON file to include a definition for the '2' value in order to clear this check.
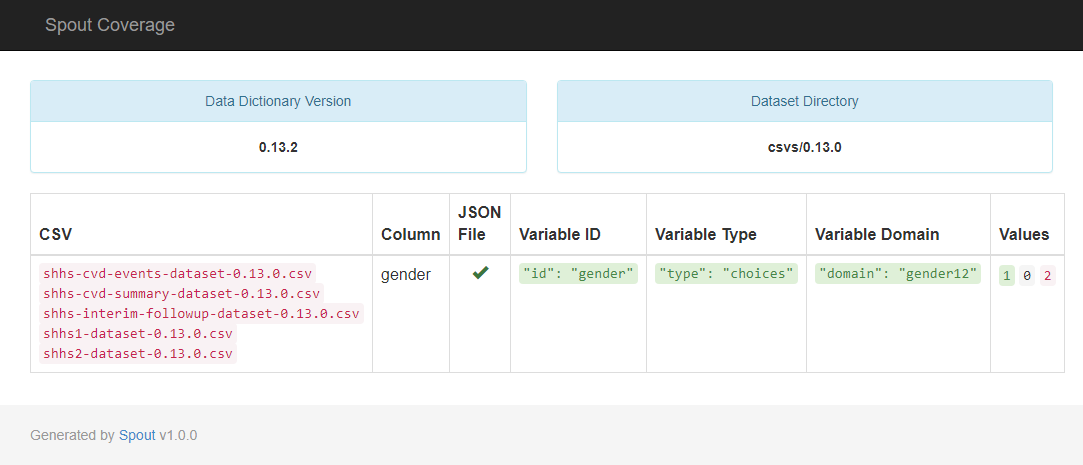
By running the coverage command throughout the data dictionary building process, Spout enables us to make corrections along the way to avoid future ambiguity for NSRR data users.
Additionally, the spout outliers command runs through the dataset files and provides information back about potential outlying values in the dataset. We try to check and confirm all outliers before publishing a new dataset version on NSRR.
Versioning
We wanted to track all changes made to the data dictionary and data over time for a given dataset. We use GitHub for this purpose. Our overarching goal in using Git is to provide NSRR data users the ability to see and revisit datasets and data dictionaries as they were at different points in time. This will be especially useful for published works, where authors can cite the specific version of a dataset used in their analyses.
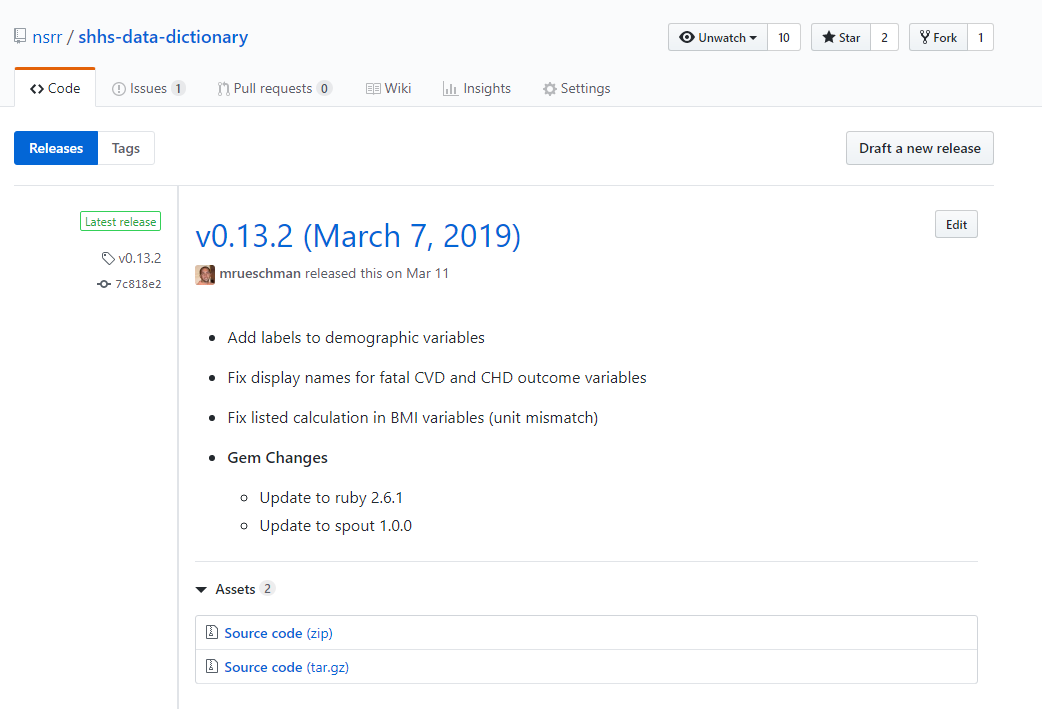
Below is a screenshot of a typical GitHub data dictionary release, including a list of the changes made in that version.
Conclusion
Spout has been an essential tool for the creation of data dictionaries on NSRR. The tool may also be used for testing and checking of non-NSRR datasets. Spout's additional, NSRR-specific features include the automated generation of data graphs and straightforward deployment of new dataset versions.